
Enterprise LLM Orchestration for Scalable Multi-Model AI Systems
Oodles builds robust LLM orchestration platforms that intelligently manage multiple large language models such as GPT, Claude, Gemini, Llama, Mistral, and open-source LLMs. Our solutions use Python, JavaScript, and high-performance backend services to deliver cost-efficient, resilient, and low-latency AI workflows through smart routing, caching, and model failover.
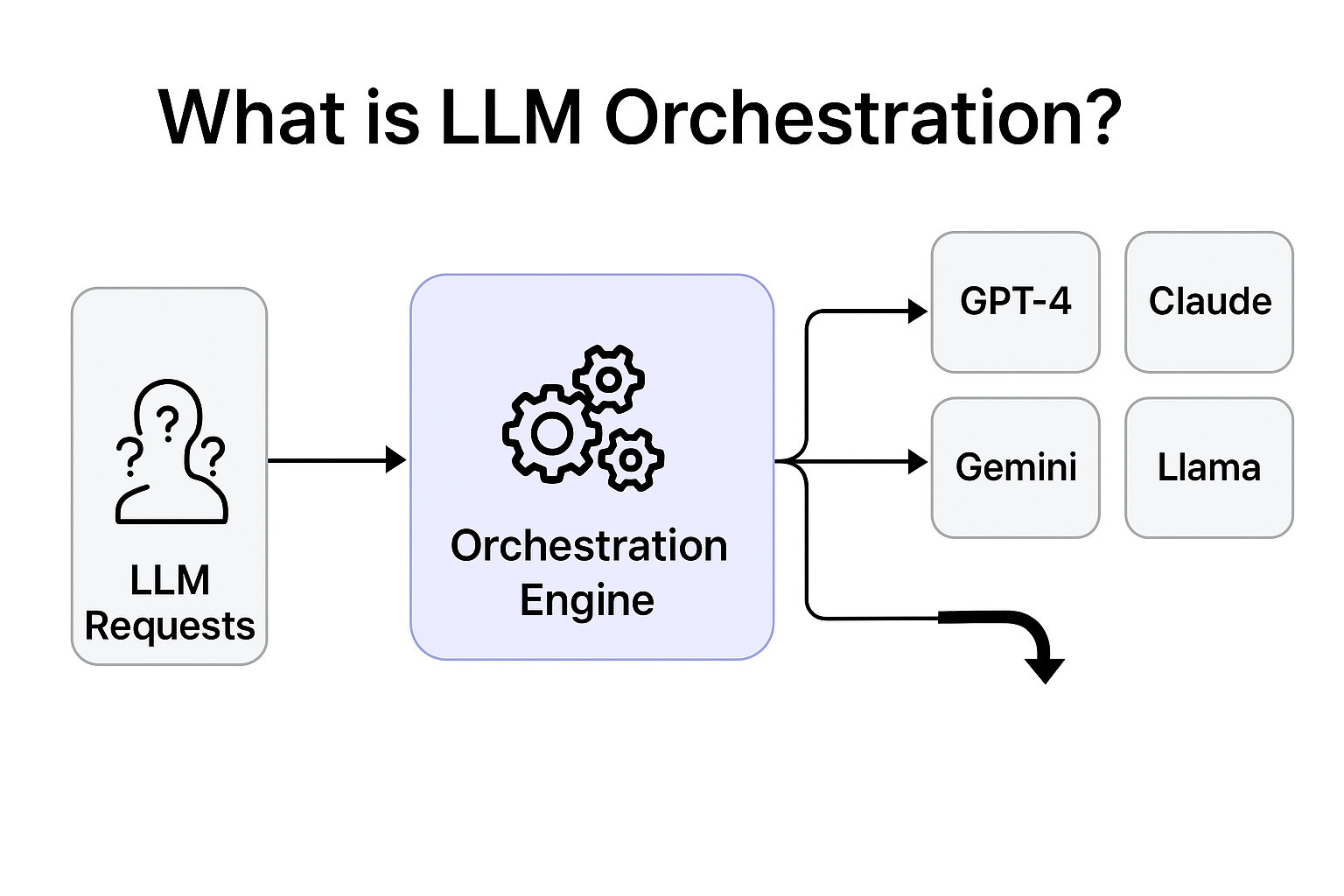
What is LLM Orchestration?
LLM Orchestration refers to the programmatic coordination of multiple Large Language Models across providers using a unified control layer. It involves request routing, fallback logic, traffic splitting, caching, monitoring, and cost governance to build scalable, reliable, and production-ready AI systems.
At Oodles, LLM orchestration systems are implemented using Python and JavaScript-based services, FastAPI or Node.js gateways, Redis caching layers, Kubernetes orchestration, and cloud-native observability stacks.
Key Features of Our LLM Orchestration Framework
Intelligent Model Routing
Route prompts dynamically to the most suitable LLM based on cost, latency, token limits, or task complexity using rule-based or ML-driven logic.
Automatic Model Fallbacks
Ensure high availability with automatic failover to secondary models during provider outages or API rate limits.
Caching & Token Optimization
Reduce inference costs and response time using Redis-based caching and fine-grained token usage controls.
Security & Rate Limiting
Protect APIs with authentication, quotas, role-based access control, and enterprise-grade rate limiting.
Why Enterprises Choose Our LLM Orchestration
- Up to 70% inference cost reduction through smart model selection
- Low-latency routing with distributed Python and Node.js services
- Unified orchestration layer for commercial and open-source LLMs
- Custom orchestration logic using rules, metrics, or ML models
- Production-ready security, auditing, and governance controls
Core Capabilities
Dynamic Model Selection
Automatically select the optimal LLM per request using metadata, historical performance, and prompt analysis.
Traffic Splitting & A/B Testing
Test new models and prompt versions in production using controlled traffic routing and shadow testing.
Observability & Cost Analytics
Monitor latency, throughput, error rates, and token spend per model using centralized analytics dashboards.
LLM Orchestration Solutions We Deliver
Oodles AI delivers enterprise-grade LLM orchestration platforms designed for resilience, transparency, and cost control across multi-model AI environments.
Cost-Optimized AI Systems
Route routine requests to cost-efficient models while reserving premium LLMs for complex reasoning tasks.
High-Availability LLM APIs
Maintain uptime with intelligent retries, provider failover, and SLA-based routing strategies.
Model Evaluation & Governance
Benchmark models, compare outputs, and govern upgrades using controlled rollout mechanisms.
Enterprise LLM Gateway
Centralized gateway with authentication, audit logs, organization-level access control, and compliance support.
Prompt Versioning & Shadow Testing
Safely deploy prompt changes using shadow traffic and real-world performance comparisons.
SLA Enforcement & Monitoring
Enforce latency and uptime targets with proactive monitoring, circuit breakers, and intelligent retries.
FAQs (Frequently Asked Questions)
Route to GPT-4 (or similar) for complex reasoning, long-context tasks, and nuanced outputs. Use smaller models (GPT-3.5, Claude Haiku, Llama) for simple classification, extraction, or short responses. We set rules based on prompt length, intent classification, or explicit user tier—often cutting costs 40–60% without quality loss.
We configure fallback chains: if the primary model fails (timeout, 5xx, rate limit), we automatically try a secondary model. We also use circuit breakers to avoid cascading failures and health checks to detect outages early. Cached responses for common queries provide a last-resort fallback.
Yes. We implement traffic splitting: e.g., 50% to GPT-4, 50% to Claude. You can compare quality (e.g., human eval, automated metrics) and cost per model. We log model, latency, and token usage for each request so you can analyze results and adjust routing.
Load balancing distributes traffic evenly across instances (round-robin, least-connections) to avoid overload. Intelligent routing selects the best model per request based on rules: e.g., route summarization to a fast model, route code generation to a capable model. Both can be combined—route intelligently first, then load-balance across that model's instances.
We cache by (prompt hash, model, params). For time-sensitive content, we set TTLs (e.g., 1 hour for FAQs, 0 for live data). We use semantic caching for similar prompts when exact match isn't required. Cache invalidation rules let you purge by topic or manually when content updates.
Yes. We proxy streaming from OpenAI, Anthropic, and others through our orchestration layer. If a fallback triggers mid-stream, we buffer and switch transparently. We also support streaming to your client while logging tokens and latency for observability.
We define rules like: "If prompt < 200 tokens and task = classification → use GPT-3.5" or "If user is free tier → use Llama, if paid → use GPT-4." We estimate cost per request (tokens × model rate) and can cap daily spend per user or route. Rules are configurable via config files or a dashboard.
Ready to orchestrate your LLMs? Let's talk



We are ISO 9001:2015 Certified
Connect with us


Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()